
KNN的流程可以分成三個部分,資料﹑訓練﹑預測。
資料分為Sample(特徵)、Label(真值)。
訓練則是利用資料的Sample與Label來運練模型。
預測為訓練好的模型來預測數值。
特徵可以把它想像是真值的標籤,例如屬於a這種的人,身高是多少﹑體種是多少等。
$samples = [[1, 3], [1, 4], [2, 4], [3, 1], [4, 1], [4, 2]];
$labels = ['a', 'a', 'a', 'b', 'b', 'b'];
接下來我們設定一個新分類器,需要兩個參數k與距離,k值是預測時候取最近的k的Sample來預測數值。
$classifier = new KNearestNeighbors($k=3, new Minkowski($lambda=4));
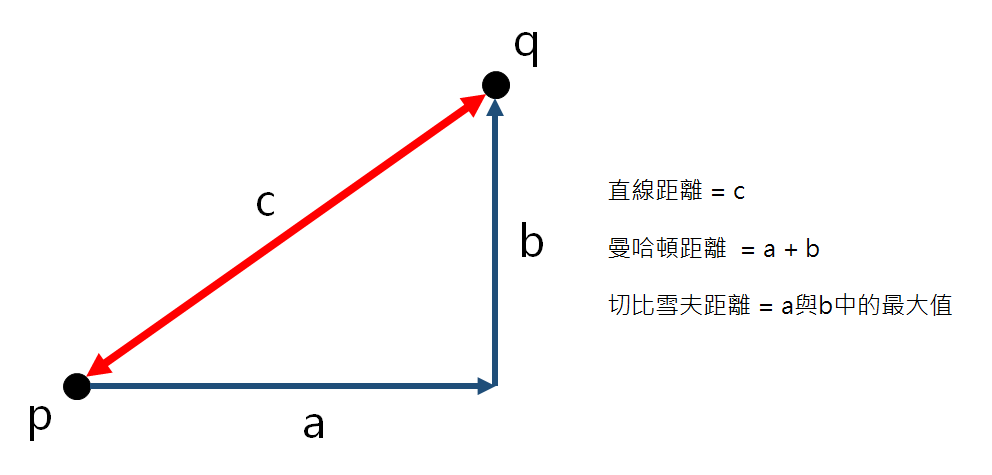
其中如何去訂定最近的距離呢?而計算距離的公式有很多種,我們介紹最常使用的3種方法。
並且利用資料訓練分類器
$classifier->train($samples, $labels);
接下來就可以試試看預測標籤啦!!
$classifier->predict([3, 2]);
完整Code:
<?php
require_once __DIR__ . '/vendor/autoload.php';
use Phpml\Classification\KNearestNeighbors;
use Phpml\Math\Distance\Minkowski;
$samples = [[1, 3], [1, 4], [2, 4], [3, 1], [4, 1], [4, 2]];
$labels = ['a', 'a', 'a', 'b', 'b', 'b'];
$classifier = new KNearestNeighbors($k=3, new Minkowski($lambda=4));
$classifier->train($samples, $labels);
echo $classifier->predict([3, 2]);
// return 'b'
echo "<br>";
var_dump($classifier->predict([[3, 2], [1, 5]]));
// return ['b', 'a']
?>
(參考來源:PHP ML)
